
C2. Data Models and Query Languages - Part 1
Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems

Hello 👋 ,
Welcome to Chapter 2! I hope you guys have revised chapter 1 by now. If not, go ahead and do it here. In chapter 2, we will compare different data models and ways to interact with these data models. In this post, along with distributed system, I am also going to give you guys some tips on newsletter industry.
Tip of the Day - When you have 20 something subscribers (BTW we have 100s of views) you must not declare, “Guys, we are growing 🥳!”. That’s just stupid.
On serious note, give me a shout out on LinkedIn. Let your connections know about our awesome community.

Introduction
What is a data model?
It means how you represent your data at various layers of your application.
For example, you may be consuming JSON APIs but when result is stored into databases (DBs), it is stored as some form of bytes which is then represented as 1s & 0s in the hardware. Each format is essentially the same information but the representation is changing as you move up or down the layer. Another intuitive example is TCP/IP stack.
When models are defined, the layers also have some assumption around its production and consumption.
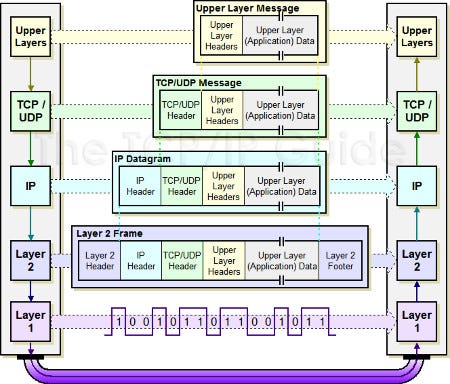
What does this chapter cover?
Comparison between different models such as relational, document, and few-graph based data models.
And the query languages associate to operate on that model.
Relational Model Versus Document Model
What is relational model?
An unordered set of tuples (rows in SQL) organized into relations (tables in SQL) called as relational model.
Relational model was initially doubted for its efficiency but later proved to be most generic model across use-cases. Now it has been tried and tested for over three decades.
Relational data models are going to stick for foreseeable future even though new data models keep emerging
The Birth of NoSQL
Where does NoSQL term come from?
NoSQL was termed emerged out of social media to organize meet ups. And spread fast and got adopted in community.
NoSQL is interpolated as Not Only SQL
What NoSQL databases were required?
Greater scalability than relational databases for very large datasets or very high write throughput
Specialised query operations & open source support
More dynamic and expressive data model requirement (schema flexibility)
What is polyglot persistence?
Using relational databases along with other non-relational databases is called polyglot persistence.
Watch the above video which is must for understanding anything in this book. Done? Good. By subscribing to this newsletter you guys are becoming that smart engineer. BUT if you don’t share with others you may still have to work on a farm and clean cistern of chicken shit! So, for your own sake, share now!
The Object-Relational Mismatch
What is impedance mismatch?
The models you create in source code and those which are stored in tables doesn't match often.
You often need a translation layer to convert database rows/relationships into objects.
The disconnect between source code model and database models is called impedance mismatch.
Object-relational Mapping (ORM) framework such as ActiveRecord and Hibernate try to reduce the boilerplate required for translation but can't completely hide the differences.
Can you give an example of impedance mismatch?
Consider LinkedIn job profile, a user can have multiple jobs on resume.
There are number of ways to store this One-to-Many mapping in databases.
Store in normalized tables and connect them with foreign keys
Store the job information as single JSON/XML object in database where database can query fields within this multi-value field
Store the job information as blob (after performing some encoding) and let the application do all interpretation
In each approach in (2), your code has to take different translation approach. Hence, you can't completely hide this disconnect between the db models and code models.
Many-to-One and Many-to-Many Relationships
What are the ways to refer a data in another table?
You can either store the data to be referenced such as ("City Name") in another table and refer it via its ID
Or you can just store the "City Name" copies as string in each row of the db

What are the pros of storing as pointer vs direct copy (denormalized vs normalized data)?
No ambiguity in values ("Greater Seattle Area" or "Greater Seattle" or "GSA") and consistency of values is maintained in a single place if you ever need to update that's the single place to refer to
Eases other operations based on these fields such as search, localization support (translating into multiple languages) etc.
So this is essentially a many-to-one relationship. For example, many user records can refer to a single record of the city in CITIES table.
Breaking down entities into separate table and then referring them by their ids into another tables is something called as normalization. If you don't know about it, that's fine. We will learn how to design a relational databases for applications from ground up in "Database Design for Mere Mortals" series. Stay tuned!
Why document models are not natural fit for many-to-* relationships?
The normalized tables are natural fit for relational DBs because their awesome join operation support
Document DBs doesn't or have weak join support. So in this case resolution of ids to actual values have to be done by application.
And it becomes more complex for document DBs if data overtime becomes highly connected and spans into many-to-many relationships.
Are Document Databases Repeating History?
Is this problem of modelling many-to-many relationship new?
No, in 70s, IBM's Information Management System (IMS) - represented information in hierarchal fashion (similar to JSON) where child records were nested within parent records.
Developers had to decide on whether to maintain copies of data or resolve the identifiers in code
At that time, this problem of modelling many-to-many relationship gave rise to network model and relational model

The network model
What is network model?
Assume instead of creating an entry for city again and again in the user objects, the user objects maintain pointer to a single city object. It is not a foreign key, it is pointer (or reference) to an object.
The city objects will also maintain links to all the parent objects i.e. user objects. Have a look at the sample model in below image.
The only way of accessing nested records is to follow a path from root to that record. Also, called as access path.
BTW the alternate name for this model is CODASYL model (Conference on Data System Languages - So a bunch of smart guys decided to name their meet up and they came up with this 🥴. Dudes, what was wrong with simple names like... hold onto your devices... Power Rangers? 😂)
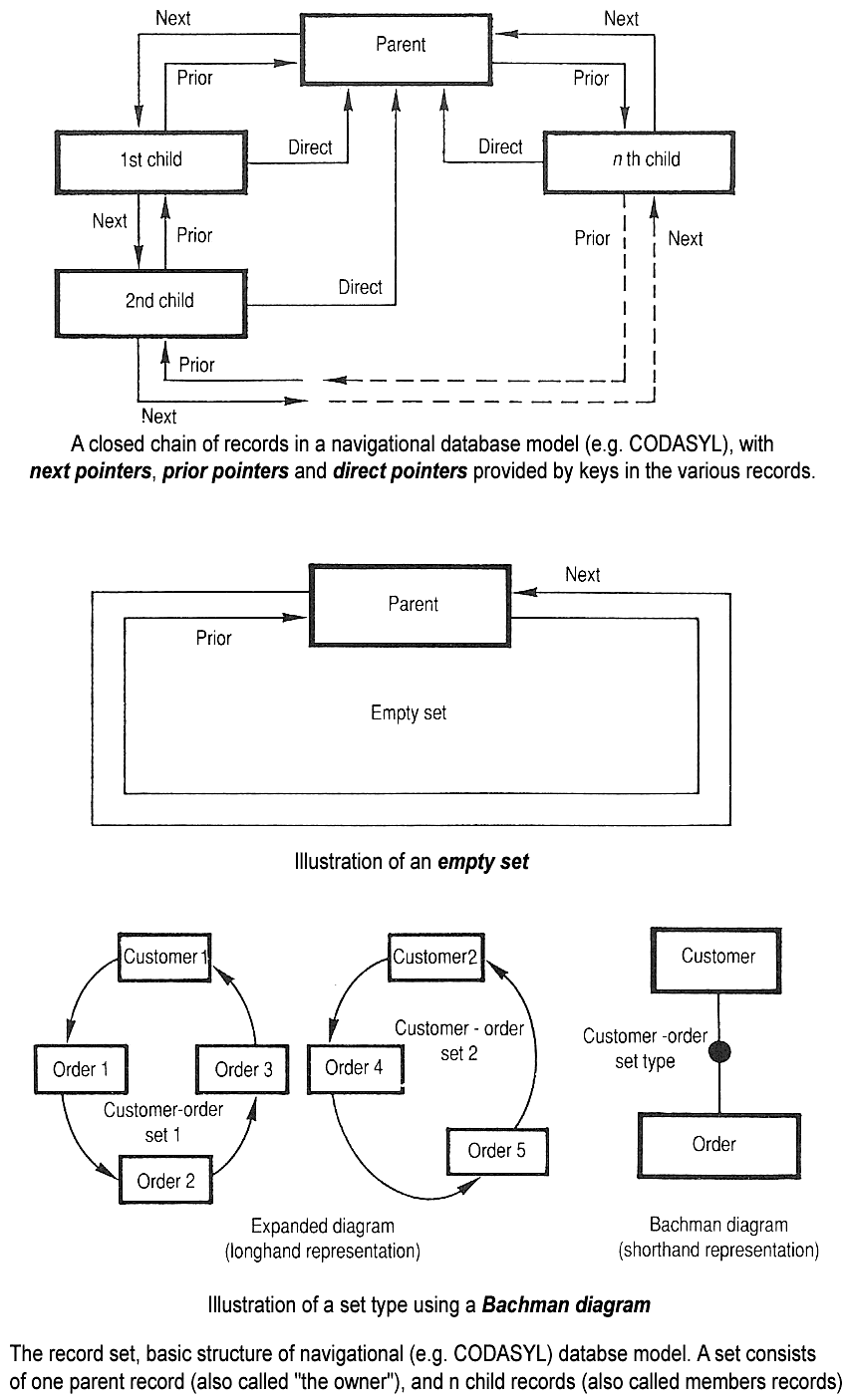
How can you query such model?
Even the database had to iterate to over the list and follow the access path to resolve the queries
How can you update the links?
If you have applied this model in today's web scale (😂 - video above) and now trying to update those links,

Basically, you will have to write a lot of manual queries to update the links.
Why would anyone use this model then?
This model worked really well in 70s because hardware very limited compared to today and this model made the efficient use of that.
Just to give an idea, in 70s the size of 400 MB storage was equivalent to today's CPU and exponentially costly compared to today's pricing.
The relational model
Why relational model became so popular?
In short, it made developer super productive and had a lot of in built capabilities, creativity, and efforts so developer's can achieve their goal intuitively.
For example, if you want to optimize your data access you will create indexes (we will dive deep into this in chapter 3), and without changing queries, the query optimizer will take care of generating & executing efficient query plan.
Additionally, it provided simple & declarative query language like SQL - which further eased the pain of other models.
Comparison to document databases
What is the similarity between relational and document databases?
The document model are similar to hierarchal DBs as they store the nested records.
But when it comes storing many-to-* relationship, relational and document model both store foreign keys which needs to be resolved either with joins or follow-up queries.
Relational Versus Document Databases Today
How are we going to compare these models?
Impedance mismatch - Which model needs less weird translation layer
Schema Flexibility - Adding/Removing attributes easily, supporting arbitrary attributes
Data locality - Storing one single blob vs spreading it across tables
Which data model leads to simpler application code?
It depends. If your application model resembles mostly with document structure it's better to pick document model.
Document model has some query restrictions though like while refering nested documents, queries are more expressive (how to get something) than declarative (get me that thing).
If your application does use many-to-many relationship, think about relational model.
IMO, Polyglot persistence (combining relational + non-relational) is a good option too. You don't have to stick with just one model. DBs are tools for solving problem and no one said you can just use one. BUT (trade-offs, that's our life) when making such choice consider the maintenance of application as well (covered in Chapter 1 - Part III).
Schema flexibility in the document model
What does it mean to have schema flexibility?
Basically you can add any arbitrary keys and values to a document and store it.
Because this is so dynamic applications needs to interpret all different structures accordingly.
This is sometimes called as being schemaless but that's not entirely correct.
Why schemaless may not be the right word?
There is an implicit schema in your application code.
More accurate terms are - schema-on-read (the structure of the data is implicit, and only interpreted when the data is read)
And schema-on-write - the structure of the data should conform to a predefined type
This is similar to dynamic and static type checking in programming languages!

Why people are skeptical of updating a relational db schema (ALTER TABLE command)?
It is a mis-conception that updating a schema (adding/removing) columns in relational db takes long time and causes downtime. It take few milliseconds. Exception is My
The reason MySQL is slow is because it copies entire table to a new table with updated schema. There are tools to workaround this limitation.
When updating schema, what are the approaches to deal with old records?
[Eager] Run an update on entire table - this may cause performance degradation during activity
[Lazy] When a record is read in application for some work, check for newly added empty fields, and if you know the value then update it.
When schema on read is advantageous?
There are different types of objects and can't be put together in single table with same schema
The structure of the data is determined by the upstream service and you don't have any control, which may change over time.
When schema on write is advantageous?
Obviously, when the structure of the data is homogenous and less likely to change over time.
Data locality for queries
What does it mean by storage locality?
Instead of looking for information across different tables and indexes the entire record is stored in one place as document.
This reduces the retrieval time and disk reads.
But general advise it to keep the documents small.
Why is advised to keep the document small given the time advantage?
Unless your application uses the entire document for processing it is a waste of bandwidth to retrieve entire document.
The DBs usually have to fetch entire doc even if they have to return a filtered set of attributes or records. And entire document needs to be rewritten if there is an update.
This performance limitation significantly reduce the set of situation in which document databases are useful.
Is concept of locality limited to document DBs?
No, Google's Spanner, Oracle, HBase etc. allow different ways of data locality in relational model as well.
Convergence of document and relational databases
How are they converging?
Relational DBs allowing XML or JSON to be stored as field and also query within that blob (MySQL, PostgreSQL)
Document DBs allowing joins (RethinkDB) or at least drivers doing it application level automatically (MongoDB)
This is good. Because at the end developer's get best of both worlds.
That’s it for today. I know it was a long post but we understand now, when making technology choices it’s not “X vs Y”, the answer is “It depends”. See you in the next part. Don’t forget to like, share, and subscribe! 😁